一个赌鬼要玩多臂老虎机,摆在他面前有 K 个臂(Arms)或动作选择(Actions),每一轮游戏中,他要选择拉动一个臂并会获得一个随机奖励(reward)(这一随机奖励来源于一个赌场设定好的分布,但赌鬼一开始不知道这一分布)。如果总共玩 T 轮,他该如何最大化奖励
多臂老虎机
随机多臂老虎机
在每一步 t=1,2,…,T 中:
- 玩家选择一个臂 at∈A={a1,…,aK};
- 玩家获得该臂对应的随机奖励 rt∼R(at)(rt∈[0,1]);
- 玩家依据过往轮次的奖励情况调整选择策略,实现奖励最大化。
说明:
- 奖励分布的均值记为 μ(ak)=E[R(ak)],k∈[K];
- 最优臂 a∗ 的奖励均值 μ∗=maxa∈Aμ(a);
- 奖励均值差异 Δ(a)=μ∗−μ(a)。
奖励均值差异和奖励均值是未知的,玩家需要通过探索来估计这些值。定义这些值是为了在上帝视角分析算法的性能。
遗憾分析
{==
伪遗憾
伪遗憾=t=1∑T(μ∗−μ(at))=μ∗T−t=1∑Tμ(at)
期望遗憾
期望遗憾=E[伪遗憾]=μ∗T−E[t=1∑Tμ(at)]
==}
由于选择策略的随机性,μ(at) 是随机变量。
一个函数 f(x) 是次线性的,如果对于所有 x,有 f(x)⩽cx 成立,其中 c 是一个常数。
在MAB问题中,我们常常关注算法遗憾界(regret bound)。一个好的遗憾界是次线性的(sub-linear),这意味着算法能逐渐学到最优臂,即
T→∞limTRegretBound(T)=0设 X1,X2,…,Xn 是独立同分布的随机变量,且 Xi∈[0,1]。则对于任意 ϵ>0,有
P(n1i=1∑nXi−E[Xi]⩾ϵ)⩽2e−2nϵ2
称 [μ−ϵ,μ+ϵ] 是置信区间(confidence interval),ϵ 是置信半径(confidence radius)。
若令 ϵ=nαlogT,则有
P(∣μ−Xn∣⩾ϵ)=P(μ−Xn⩾nαlogT)⩽2T−2α,∀α>0
一般取 α=2
贪心算法
 贪心算法
贪心算法
贪心算法期望遗憾界
贪心算法期望遗憾界为 O(T32(KlogT)31)。
分析框架:好事件 vs. 坏事件
我们将利用阶段的期望遗憾 E[R(exploitation)] 分解为两部分:
E[R]=E[R∣E]⋅P(E)+E[R∣Eˉ]⋅P(Eˉ)
-
事件 E (好事件): 我们的采样估计是"准确"的。具体来说,所有臂 a 的样本均值 Q(a) 与其真实均值 μ(a) 的差距都小于某个范围 rad。
E={∀a,∣μ(a)−Q(a)∣≤rad}
其中我们定义 rad 为 N2logT。
-
事件 Eˉ (坏事件): 事件 E 的补集,即至少有一个臂的采样估计"不准确",超出了 rad 的范围。
分析坏事件 Eˉ 的贡献
根据霍夫丁不等式和联合界,坏事件发生的概率 P(Eˉ) 极小:
P(Eˉ)≤a=1∑KP(∣μ(a)−Q(a)∣>rad)≤a=1∑K2e−2N(rad)2=a=1∑K2e−4logT=2KT−4
在坏事件中,最坏情况下的遗憾为 T。因此,这部分对总遗憾的贡献可以忽略不计:
E[R∣Eˉ]⋅P(Eˉ)≤T⋅O(KT−4)=O(KT−3)
分析好事件 E 的贡献
假设我们处在"好事件" E 中,即 ∣μ(a)−Q(a)∣≤rad 对所有臂都成立。
只有当我们选错了臂(即选择了次优臂 a 而非最优臂 a∗)时,才会产生遗憾。这种情况发生的条件是 Q(a)>Q(a∗)。
利用好事件的定义,我们可以推导出一系列不等式:
μ(a)+rad≥Q(a)>Q(a∗)≥μ(a∗)−rad
整理上式可得,单步遗憾的上界为:
Δa=μ(a∗)−μ(a)<2⋅rad
这意味着,在好事件中,即便我们选错了,这个次优臂也不会太差。因此,利用阶段的总遗憾上
界为:
E[R(exploitation)∣E]≤(T−KN)⋅(2⋅rad)
综合与优化
将所有部分的遗憾相加,我们得到总期望遗憾 R(T) 的上界:
E[R(T)]≲探索遗憾(K−1)N+利用遗憾(T−KN)⋅(2⋅rad)+可忽略O(KT−3)
代入 rad 的定义,并忽略一些小项:
E[R(T)]≲KN+2TN2logT
为了最小化这个上界,我们需要平衡探索成本(随 N 增加)和利用遗憾(随 N 减小)。我们令两项的量级相等来找到最优的 N:
KN≈TNlogT⟹N3/2≈KTlogT⟹N≈(KTlogT)2/3
将这个最优的 N 代回遗憾表达式 KN 中:
E[R(T)]≈K⋅(KTlogT)2/3=K⋅K2/3T2/3(logT)1/3=K1/3T2/3(logT)1/3
最终得到遗憾界为:
E[R(T)]=O(T32(KlogT)31)
 $\epsilon$-贪心算法
$\epsilon$-贪心算法
上置信界算法


UCB算法期望遗憾界为 O(KTlogT)。
汤普森采样算法
汤普森采样采用贝叶斯方法来解决探索-利用困境。其核心思想是为每一个臂(选项)维护一个关于其奖励概率的"信念",这个"信念"通过一个概率分布来表示。
在做决策时,算法并不是直接选择当前看起来最好的臂,而是为每个臂的"信念"分布进行一次采样,然后选择被采样出最高值的那个臂。
在获得奖励后,算法会根据奖励结果更新被选择臂的"信念"分布,使其更接近真实情况。
具体而言,汤普森采样算法通常使用 Beta 分布来作为每个臂的奖励概率的信念分布。这在奖励为二元(成功/失败,即伯努利试验)的场景下尤其方便。

这个过程会不断重复,通过贝叶斯更新,每个臂的 Beta 分布会越来越准确地反映其真实的成功概率,从而使得算法能更快地收敛到最优臂。

Beta分布经过更新$\alpha$和$\beta$后仍然是Beta分布。
对抗性多臂老虎机
对抗性多臂老虎机(Adversarial MAB)问题是多臂老虎机(MAB)问题的一种变体。
与随机多臂老虎机问题不同,对抗性多臂老虎机中的奖励(或代价)是由对手动态生成的,而不是从固定的奖励分布中随机抽取的。对手可能会根据玩家的策略进行调整,从而形成对抗性。其基本模型如下:
在每一步 t=1,2,…,T 中:
- 玩家在行动集合 [n]={1,…,n} 上选择一个概率分布 pt;
- 对手在已知 pt 的情况下选择一个代价向量 ct∈[0,1]n,为每个行动分配一个代价;
- 玩家根据概率分布 pt 选择一个行动 it,并观察到该行动的代价 ct(it);
- 玩家学习整个代价向量 ct,以调整未来的策略。
注:
- 玩家的目标是选择一个策略序列 p1,p2,…,pT,使得总代价最小化(相对于奖励最大化),即最小化期望代价 Eit∼pt[∑t=1Tct(it)]。
- 对手不一定真实存在,这只是一个最坏情况分析;
- 在这种情况下,玩家不仅能学习到所选行动的代价,还能学习到所有行动的代价,因此这是一个全反馈的情境,与之前的情况不同。
你面前有一排老虎机。每台机器的中奖概率是固定的,但你不知道具体是多少。你的任务是通过不断尝试,尽快找出哪台机器最好(中奖概率最高),然后一直玩那台。这就像是在和一个"诚实但守口如瓶"的赌场老板玩,规则是固定的,只是你不知道而已。
现在,我们来看看对抗性多臂老虎机:
这次,你面对的不再是固定的机器,而是一个"狡猾的"赌场老板。这个老板知道你心里在想什么。
- 不再有固定的"最佳选择":与之前不同,这里没有哪一台机器是永远最好的。老板会每一轮都重新设置所有机器的"代价"(你可以理解为玩一次要花的钱,或者奖励的反面)。
- 对手知道你的策略:在你出手之前,你可能会想好一个策略,比如"我今天有70%的可能去玩1号机,30%的可能去玩2号机"。这个狡猾的老板能看穿你的策略。
- 对手会针对你:老板看到你今天大概率要玩1号机,他就会立刻把1号机的代价调得非常高,让你付出惨重代价。同时,他可能会把你基本不考虑的那些机器的代价调得很低。
- "事后诸葛亮":在你玩完一把之后(比如你按计划玩了1号机,付出了高昂代价),老板会把所有机器这一轮的代价都告诉你。你会发现,果然你没选的那些机器代价都很低。这个"事后全盘信息"(在模型里叫 full feedback)是这个模型的一个关键特点,能帮助你调整下一轮的策略。
遗憾的定义
第一种遗憾定义的想法是,与所有轮次结束后(每一轮的成本都已知)的事后最优作差,然而下面的例子表明这一定义是不合理的
设行动集合为 {1,2},在每一轮 t,对手按如下步骤选择代价向量:假设算法选择一个概率分布 pt,如果在此分布下选择行动 1 的概率至少为 21,那么 ct=(1,0),反之 ct=(0,1)。在此情况下,在线算法期望代价至少为 2T,而在事先知晓代价向量的情况下,最优算法的期望代价为 0。
这一例子表明,与事后最优比较可能出现线性级别的遗憾,因此这一基准太强了。因此转而将遗憾定义为在线算法与最优固定行动事后代价之差。
固定代价向量 c1,c2,…,cT,决策序列 p1,p2,…,pT 的遗憾为
RT=Eit∼pt[t=1∑Tct(it)]−i∈[n]mint=1∑Tct(i).
即遗憾被定义为和每轮都选择同一行动的最优的固定行动的代价之差,这样的定义相对而言更加合理:
- 在前面的例子中,固定策略序列(全选 0 或 1)的遗憾不再是简单的 0;
- 平均遗憾:TRT。若 T→∞,RT=o(T),则称算法是无遗憾(no-regret)的,等价的即 RT 关于 T 是次线性的;
- 这一定义的合理在于,有自然的算法实现无遗憾,但无悔的实现也不是平凡的。
跟风算法
跟风算法指在每一个时间点t,选择最小累积代价
s=1∑t−1cs(i)
的行动i。
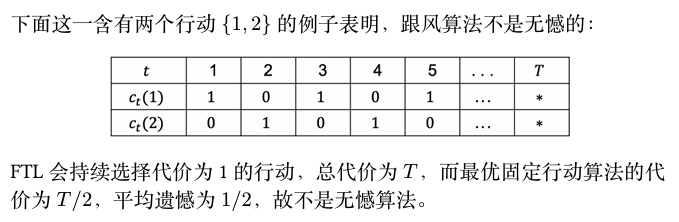 FTL算法不是无悔的
FTL算法不是无悔的
若算法是无悔的,则策略是随机化的,只需要证明若策略是确定性的,则算法不是无悔的。
对于确定性算法,对手可以直接推断出我们的行为,从而在每一步设置我们选择的行为代价为1,其它代价为0;
这样,总代价为T,而最优固定行动的代价不会超过nT,因此遗憾为1−n1,不是无悔的。
如果采用随机策略,则对手只能推断出我们的概率分布 pt,而不能推断出我们的具体行动 it∼pt,因此对手无法完美利用我们的算法。
MWU算法
考虑一个简化的在线学习场景,每个行动的代价之可能为 0 或 1,并且存在一个完美的行动,其代价永远为 0(但玩家一开始不知道哪个是完美行动),是否存在次线性遗憾的算法?
观察:只要一个行动出现了非零代价,那就可以永远排除它,但我们并不知道剩余行动中哪个最好;
可以设计算法如下:对每一步 t=1,2,…,T,记录截至目前从没出现过代价 1 的行动,然后在这些行动中根据均匀分布随机选择一个行动。
对于任意 ϵ∈(0,1),下面两种情况之一一定会发生:
- Sgood 中至少 ϵk 个行动有代价 1,此时这一阶段的期望代价至多为 ϵ(均匀分布,每个行动的概率为k1,选中ϵk个行动的概率为ϵ,因此期望代价为ϵ);
- Sgood 中至多 ϵk 个行动有代价 1,每次出现这一情况时,下一步就可以排除掉至少 ϵk 个行动,因此这种情况最多出现 log1−ϵn1 次(每一次都只剩下k(1−ϵ)个行动,因此最多出现m次,有n(1−ϵ)m=1)。
因此总的遗憾至多为(放缩后)
RT⩽T×ϵ+log1−ϵn1=Tϵ+−ln(1−ϵ)lnn⩽Tϵ+ϵlnn
最后的不等号导来源于 −ln(1−ϵ)≥ϵ(0<ϵ<1)。显然当 ϵ=Tlnn 时,RT≤2Tlnn,即次线性遗憾。
 更一般的情况
更一般的情况
初始化权重为1,每次挑选之后,查看此次的代价向量ct,如果ct(i)=1,则将i的权重变小,下一次根据权重随机挑选
上图中第二种算法就是乘性权重(Multiplicative Weights Update, MWU)算法。算法的直观是,根据每个行动在之前阶段的表现来决定下一阶段的权重,即表现好的行动权重增加,表现差的行动权重减少。
乘性权重算法在之前的问题设定下的遗憾至多为 O(Tlnn)。



多臂老虎机应用
动态定价问题
假设你要出售一份数据,你知道会有 N 个人来购买你的数据,并且每个人对数据的估值 v 都完全一致,都在 [0,1] 中。买家是逐个到达的,你需要提供一个价格 p,如果 v≥p,买家就会购买你的数据,否则买家会离开。你的目标是尽快地学习到 v 的值,误差范围是 ϵ=N1。
如果你确遇到了最坏的情况,logN 次搜索之后,可以设置到价格 p≥vˉ−N2,其中 vˉ 是我们第 logN 轮学习到的值;
在这种情况下,N 轮之后的总收益是:
0前 log N 轮+(N−logN)(v−N2)后 N-log N 轮≈vN−vlogN−2.
- 则二分搜索的遗憾为 R≈vN−(vN−vlogN−2)=vlogN+2;
- 这是最小的可能遗憾吗?
存在一个改进的算法,使得其遗憾至多为 1+2loglogN。
- 尽管二分搜索是在没有任何先验信息的情况下能搜索到 N 的最快算法, 但当猜测的 pi>v 时, 卖家一分钱也赚不到;
- 也就是说, 二分搜索在向上探索的时候可能过于激进, 因此改进的算法需要在探索时更加保守
改进算法
 改进算法
改进算法
首先需要分析区间长度 bi−ai 的特点,有如下结论:
Δi=2−2j−1,并且当 Δi+1=(Δi)2 时,bi+1−ai+1=Δi=Δi+1。
第一个结论根据数学归纳法可以证明:
- 当 i=1 时,Δ1=21=2−20;
- 假设对于 i=k 成立,即 Δk=2−2j−1,则
Δk+1=(Δk)2=(2−2j−1)2=2−2j−1⋅2=2−2j
第二个结论,当 Δi+1=(Δi)2 时,根据算法直接得到 bi+1−ai+1=Δi=Δi+1。
- 在 bi−ai≤N1 后,总的遗憾最多为 N×N1=1;
- 因此重点在于分析达到这一步之前的遗憾;
- 在达到这一步之前 Δ 更新了多少次?
- loglogN:令 2−2i=N1,则 2i=logN,则 i=loglogN;
- 接下来就要证明每个 Δi 内产生的遗憾是有限的。
任意的步长 Δi 内的遗憾至多为 2。
综合上述两个引理可以得到改进算法的遗憾为 1+2loglogN。