合作博弈
一个具有可转移效用(transferable utility)的合作博弈(或称为 TU 博弈)是一个满足如下条件的二元组 :
- 是一个有限的参与者集合;一个 的子集被称为一个联盟(coalition),全体联盟构成的集合记为 ;
- 称为该博弈的特征函数(characteristic function),对于任意的 , 表示联盟 的价值(worth),且满足
考虑一个场景,假设有三个人A,B,C,他们的特点分别如下:
- A擅长于发明专利,依靠这一才能年收入达17万美元;
- B有机敏的商业嗅觉,能准确发掘潜在市场,创建商业咨询公司年收入可达15万美元;
- C擅长市场营销,开办专门的销售公司年收入可达18万美元。
显然,三个人的才能互补,于是他们考虑合作:
- B可以为A提供市场资讯,将A的发明专利卖给市场上最有需求的人,这样他们合作每年收入可达35万美元;
- C利用他的才能销售A的发明专利,合作年收入可达38万美元;
- 当然B和C也可以合作组建一个提供市场咨询和销售一体化的公司,这样每年合作收入可达36万美元;
- 最后A,B,C如果共同合作,A在B的建议下发明最符合市场需求的专利,然后由C进行销售,这样他们合作每年收入可达56万美元。
现在可以用定义形式化这一博弈:不难得到 ,全体联盟构成的集合
则该场景可以表示为一个合作博弈 ,其中特征函数 定义如下:
一个合作博弈 的解概念是一个函数 ,它将每个博弈 与一个 的子集 联系起来。如果对于任意的博弈 都是一个单点集,则称这一解概念为单点解(point solution)。
更通俗地说,合作博弈的解概念就是一个将每个博弈映射到一个可行的收入分配集合的函数,这个集合中的每个元素是一个分配向量 ,其中 表示参与者 在当前分配下可以获得的收入。
Example

核
一个合作博弈 的核(core)是一个解概念 ,其中 由满足以下两个条件的分配向量 组成:
- 有效率的(efficient) : ,即所有参与者分完了整个联盟的全部收入;
- 联盟理性(coalitionally rational) : 对于任意的 ,有 ,即对于任何联盟而言,他们在大联盟中分配到的收入一定不会比离开大联盟组成小联盟获得的收入少。
Example

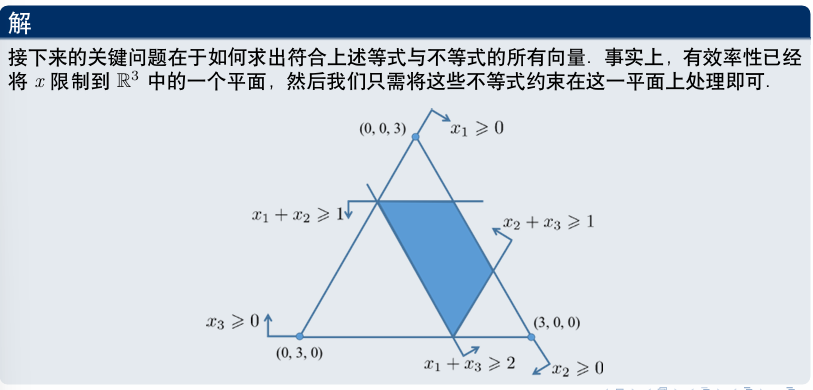
也存在核为空集的博弈

Shapley Value
想象一下,你和几个朋友一起合作完成一个大项目,最后赚了一大笔奖金。现在要分这笔钱,怎么分才最公平呢?每个人都觉得自己的贡献最大。
沙普利值就是为了解决这个“公平分钱”问题而提出的一种数学方法。
一个参与者应得的报酬,等于他/她在所有可能的合作顺序中,为团队带来的“平均边际贡献”。
我们来拆解这个核心思想:
- 边际贡献 (Marginal Contribution)
这指的是当你加入一个已经存在的团队时,你为这个团队额外增加了多少价值。
- 比如,原来团队能赚100万,你加入后,团队能赚125万。那么你这次的“边际贡献”就是25万。
-
所有可能的合作顺序 你加入团队的时机不同,你的“边际贡献”可能也不同。
- 如果你是 第一个 加入的,你的贡献就是你单干的价值。
- 如果你是 最后一个 加入的,你的贡献是“满员团队的价值”减去“少你一人的团队价值”。
- 为了公平,我们必须考虑到你加入团队的所有可能顺序(第一个加入、第二个加入……最后一个加入)。
-
取平均值 沙普利值会计算出你在每一种加入顺序下的“边际贡献”,然后把它们全部加起来,再除以总的顺序数量,得到一个平均值。这个平均值,就被认为是你应该得到的、最公平的报酬。
我们用这个思想来计算一下A应该分多少钱:
总共有 种可能的合作顺序:
| 顺序 | A的“边际贡献”计算 | A的贡献值 |
|---|---|---|
| A, B, C | A第一个加入,贡献是 v({A}) |
17 |
| A, C, B | A第一个加入,贡献是 v({A}) |
17 |
| B, A, C | B先来,A再加入。贡献是 v({A,B}) - v({B}) = 35-15 |
20 |
| C, A, B | C先来,A再加入。贡献是 v({A,C}) - v({C}) = 38-18 |
20 |
| B, C, A | B,C先来,A最后加入。贡献是 v({A,B,C}) - v({B,C}) = 56-36 |
20 |
| C, B, A | C,B先来,A最后加入。贡献是 v({A,B,C}) - v({C,B}) = 56-36 |
20 |
现在我们把A在所有情况下的贡献加起来求平均:
所以,按照沙普利值的公平分配方案,A应该得到19万美元。
用同样的方法,我们也可以算出B和C的应得报酬。
沙普利值的性质
- 提供唯一的“公平解”:与“核(Core)”可能存在多个解或无解的情况不同,沙普利值对于任何合作博弈,总能给出一个唯一的、确定的分配方案。这在现实决策中非常重要。
- “公平”有严格的数学公理支撑:它的公平性不是凭感觉,而是满足一系列被广泛接受的公平原则(如:贡献相同的人收益相同;没有贡献的人收益为零;总收益被全部分配完毕等)。
Shapley Value 的形式化定义
令 为一个单点解,即对于任意的合作博弈 (其中 ), 都是一个单点集,也就是唯一一个 中的向量。我们定义 为向量 中的第 个位置的元素,即 表示参与者 在博弈 中的分配到的收入。
-
一个解概念 是有效率的 (efficiency),若对于任意的合作博弈 (其中 ),有 。这与核的要求一致。
-
一个解概念 是对称的 (symmetry),若对于任意的合作博弈 和任意的 ,如果对于任意的 ,有 ,则 。这意味着如果两个参与者对所有可能的合作子集的贡献相同,那么他们应该得到相同的分配。
-
一个解概念 是零贡献者的 (null player),若对于任意的合作博弈 和任意的 ,如果对于任意的 ,有 ,则 。这意味着如果一个参与者对任何合作子集都没有增加价值,那么他们的分配应该为零。
Example

设定
即在排序 中位于参与人 前面的所有参与人的集合。例如若在排序 下参与人 排在了第一位,那么 。
令 是一个合作博弈,其中 ,参与人 的沙普利值定义为
其中 表示所有参与人的排列集合, 表示在排列 中位于参与人 前面的所有参与人的集合。
这个公式表示在所有可能的参与人排列中,计算参与人 的边际贡献的平均值。
对于合作博弈 ,其中 ,参与人 的沙普利值定义为
其中 表示不包含参与人 的所有子集。这个公式表示在所有可能的子集中,计算参与人 的边际贡献的加权平均值。
即对于前面是集合 的子集,后面是集合 的子集,一共有 种组合,每种组合的贡献是 。总的情况数是 。
留一法
一个常见的思路是采用逆向思维来评估数据集 的贡献,即考虑在没有数据 的情况下,模型性能会受到多大影响。这就是留一法(leave-one-out,简称 LOO)的核心思想。基于留一法,数据价值 的定义如下:
即,使用完整数据集训练的模型表现与去除数据 后训练的模型表现之间的差异。换句话说,这表示在已有其他数据集的情况下,加入 后模型性能的提升程度。这个定义的直观合理性在于,如果数据 对模型贡献很大,那么去除 后模型表现应当显著下降,即 的值应当较大。
然而,留一法存在一个缺陷:如果 ,显然 ,因为去掉数据 或 后,由于存在完全重复的数据,模型表现不会受到影响。
Data Shapley
Data-Shapley 的公式定义基于 Shapley 值的概念,用于评估数据集中每个数据点 对模型性能的贡献。
首先,我们来看第一个公式:
Note
其实这个形式可以转化为我们之前考虑的组合的形式,只需要在分子分母同时乘以 即可。
而
这就是我们熟悉的形式了
- : 表示数据点 的 Data-Shapley 值。它量化了 对模型性能的平均贡献。
- : 数据集中所有数据点的总数。
- : 是原始数据集 中不包含 的任意子集(联盟)。
- : 表示从整个数据集 中移除数据点 后剩余的数据集。
- : 表示 是从 中选择的子集。
- : 表示使用数据集 训练模型后获得的性能(例如,准确率、F1 分数等)。
- : 表示在数据集 的基础上,加入数据点 后训练模型获得的性能。
- : 这部分代表了在给定联盟 的情况下,数据点 对模型性能的“边际贡献”(marginal contribution)。
- : 这是一个二项式系数,表示在剩余的 个数据点中,选择 个数据点组成联盟 的方式的数量。这个项用于对不同大小的联盟进行加权,确保每个数据点在所有可能的联盟中的边际贡献被公平地考虑。
- : 整个表达式表示对 在所有可能联盟中的边际贡献进行平均。前面的 是一个归一化因子。
进一步地,引入 的概念:
- : 表示加入数据集 后,对所有大小为 的联盟带来的模型训练结果提升的平均值。它被称为 对大小为 的联盟的“边际贡献”。
- : 表示只考虑大小为 的联盟 。
- : 用于对所有大小为 的联盟中 的边际贡献进行平均。
基于此,Data-Shapley 的定义可以进一步改写为:
这个公式解释了 Data-Shapley 值是数据点 对所有不同大小的联盟的边际贡献的平均。具体来说:
- 对于每个可能的联盟大小 (从 0 到 ),计算 对该大小的所有联盟的平均边际贡献 。
- 然后,将这些不同大小联盟的平均边际贡献 加起来,再除以 。
在 Data-Shapley 中,数据对任意大小的联盟的贡献是平等对待的。也就是说,一个数据集对小的联盟的贡献和对大的联盟的贡献在 Data-Shapley 中具有相同的权重。然而,一个自然的问题是,当联盟本身已经很大时,此时再加入一个数据集,对联盟的贡献通常而言会比较小,所以对较大联盟的边际贡献应该适当给予降低。因此更进一步,在数据估值中,如果对较大联盟的边际贡献权重适当给予缩小,更加重视对较小联盟的边际贡献,可能对数据集的评估会更加准确。基于此,Beta-Shapley 的定义为:
其中, 是一个权重因子,用于调整不同大小联盟的边际贡献在总和中的权重。
Data-Banzhaf 的定义如下:
从 Data-Banzhaf 的公式中可以看出,实际上是将 对所有 个联盟 的贡献取平均。与 Data-Shapley 不同,Data-Banzhaf 对每个单独的联盟的权重是相同的。
- : 表示所有可能的联盟数量。
- : 表示数据点 对联盟 的边际贡献。
Data-Banzhaf 提供了一种不同的视角,即对随机学习算法的优化进行改进。

另外一种方法是,将跑道视为分段修建。假设各航空公司的需求已排序,即 。我们将成本分摊过程分解如下:
- 第一段 (长度 0 到 ):
- 成本: 。
- 受益者: 所有 家公司。
- 分摊: 成本由 家公司平分,每家分摊 。
-
第二段 (长度 到 ):
- 成本: 。
- 受益者: 剩下 家公司。
- 分摊: 成本由 家公司平分,每家分摊 。
-
第 段 (长度 到 ):
- 成本: 。
- 受益者: 剩下 家公司。
- 分摊: 成本由 家公司平分,每家分摊 。
... 以此类推,直到最后一段。
航空公司 需要长度为 的跑道,因此它参与了前 段的成本分摊。其应付的总成本(即沙普利值)为: