垃圾回收(Garbage Collection, GC)是运行时系统(而非编译器)的职责:自动回收堆上已分配但不再使用的内存,无需程序员显式调用 free。
Garbage:已分配但不再被使用的存储空间。
理想情况:任何未来不会被用到的记录都是垃圾。但精确判断这一点是不可判定的(与 liveness 问题类似),因此 GC 使用保守的可达性近似。
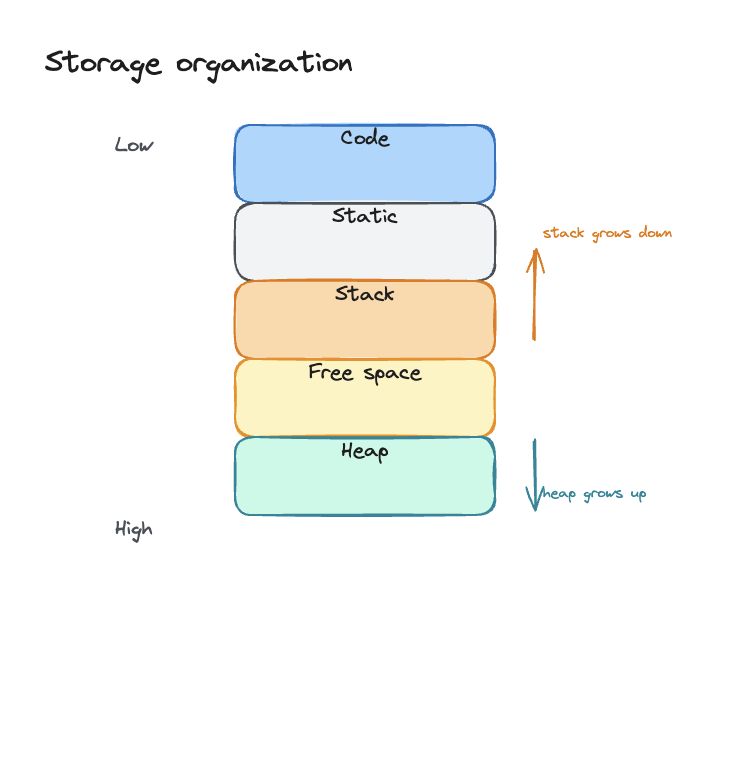
存储组织
程序内存的典型划分:
| 区域 | 内容 |
|---|---|
| Code | 可执行目标代码 |
| Static | 编译时大小已知的数据:全局常量、编译器生成的数据 |
| Stack | 过程调用产生的激活记录(activation records) |
| Heap | 程序控制下动态分配/释放的数据:C 的 malloc/free,Java 的 new |
手动 vs 自动内存管理
手动管理(C/C++)
- 使用
malloc/free或new/delete; - 容易出错:内存泄漏(忘记 free)、重复释放(double free)、使用已释放内存(use-after-free);
- 存储 bug 难以定位:错误效果可能在时间和空间上远离 bug 源头。
自动管理(GC)
- 回收内存是自动的;
- 由运行时系统(与编译代码链接的支持程序)执行,而非编译器本身。
可达性(Reachability)
基本数据结构:有向图
- 节点:程序变量 + 堆分配的记录;
- 边:指针指向关系;
- 根(Roots):程序变量,包括:
- 寄存器中的指针;
- 栈上的局部变量/形式参数;
- 全局变量。
节点 n 可达 ⟺ 存在从某个根 r 出发的有向路径 r → … → n。
保守近似
| 关系 | 说明 |
|---|---|
| 不可达 → 垃圾 | 安全:不可达的记录一定是垃圾 |
| 垃圾 → 可能可达 | 保守:某些可达记录实际上可能已死,但 GC 会保留它们 |
因为精确判断 dynamic liveness 不可判定,GC 用可达性作为保守近似。
Mark-and-Sweep Collection(标记-清除)
两阶段算法
Mark 阶段:从根出发,用 DFS 遍历可达图,标记所有访问到的节点。
function DFS(x)
if x 是指向堆的指针 且 record x 未标记
mark x
for each field fi of record x
DFS(x.fi)
Sweep 阶段:线性扫描整个堆,将未标记的节点链接到空闲列表(freelist),并清除已标记节点的标记(为下次 GC 做准备)。
// Mark
for each root v
DFS(v)
// Sweep
p ← heap 首地址
while p < heap 末地址
if record p 已标记
unmark p
else
p.f1 ← freelist // 链接到空闲列表
freelist ← p
p ← p + sizeof(record p)
成本分析
设 H = 堆大小,R = 可达数据量:
| 阶段 | 时间 |
|---|---|
| Mark | O(R) |
| Sweep | O(H) |
| 总时间 | c₁R + c₂H |
GC 回收了 H − R 个字的可用内存,摊销成本(每分配一个字的开销):
- 当 R 接近 H 时,成本极高(每次只回收少量垃圾);
- 当 时,成本趋近于 (约 3 条指令/字)。
- 收集器可以直接测得 和 ;若一次收集后 仍然过高(例如 ),说明 heap 太小,应向操作系统申请更大的堆,否则之后会频繁 GC。
显式栈 vs 指针反转
问题:递归 DFS 的栈深度可能达到 H(比堆还大)。
显式栈:用数组代替递归,H 个字而非 H 个激活记录,但仍需辅助栈空间。
显式栈版本把待扫描节点作为 worklist:
if x 是指针且未标记
mark x
push x
while stack 非空
x ← pop()
for each field fi of x
if x.fi 是指针且未标记
mark x.fi
push x.fi
指针反转(Pointer Reversal):把 DFS 栈存在图本身中——遍历 x.fi 时,让 x.fi 指向其父节点;回溯时恢复原值。无需额外栈空间,每个记录需一个 done 字段记录已处理到第几个域。
function DFS(x)
if x 是指针 且 x 未标记
t ← nil
mark x; done[x] ← 0
while true
i ← done[x]
if i < #fields in x
y ← x.fi
if y 是指针 且 y 未标记
x.fi ← t; t ← x; x ← y // 指针反转,入栈
mark x; done[x] ← 0
else
done[x] ← i + 1
else
y ← x; x ← t // 出栈
if x = nil then return
i ← done[x]
t ← x.fi; x.fi ← y // 恢复指针
done[x] ← i + 1
碎片问题
| 类型 | 说明 |
|---|---|
| External fragmentation | 想分配大小为 n 的记录,有很多小于 n 的空闲块,但没有刚好 n 的 |
| Internal fragmentation | 分配了过大的记录(如对齐要求),未使用的内存在记录内部 |
解决方案:按大小维护多个 freelist,freelist[i] 存放所有大小为 i 的记录;分配时直接取对应链表头;大记录可拆分。
Reference Counts(引用计数)
基本思想
每个记录维护一个引用计数:指向该记录的指针数量。
- 新引用建立时,计数 +1;
- 引用被覆盖/销毁时,计数 −1;
- 计数归零 → 该记录变为垃圾,可立即回收。
实现
编译器在每个赋值 x.fi ← p 处插入额外指令:
z ← x.fi // 旧值
z.count ← z.count - 1 // 旧引用计数减
if z.count = 0 then putOnFreelist(z)
x.fi ← p
p.count ← p.count + 1 // 新引用计数加
问题
| 问题 | 说明 |
|---|---|
| 循环垃圾无法回收 | 循环引用的对象每个计数都 ≥1,但整体上已不可达 |
| 开销极高 | 每次指针赋值需多条指令更新计数;即使优化后仍很昂贵 |
解决循环:要求程序员手动打破循环,或结合偶尔的 mark-sweep 回收循环垃圾。
优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单 | 无法回收循环垃圾 |
| 即时回收 | 赋值操作显著变慢 |
| 增量式(无停顿) | 大回收时可能卡顿 |
Copying Collection(复制收集)
基本思想
将堆分为两个半区:
- from-space:程序当前使用的区域;
- to-space:GC 时未使用的区域。
GC 时,遍历可达图,把所有可达记录复制到 to-space 的连续区域;复制完成后,from-space 全部变为垃圾。然后交换 from-space 和 to-space 的角色。
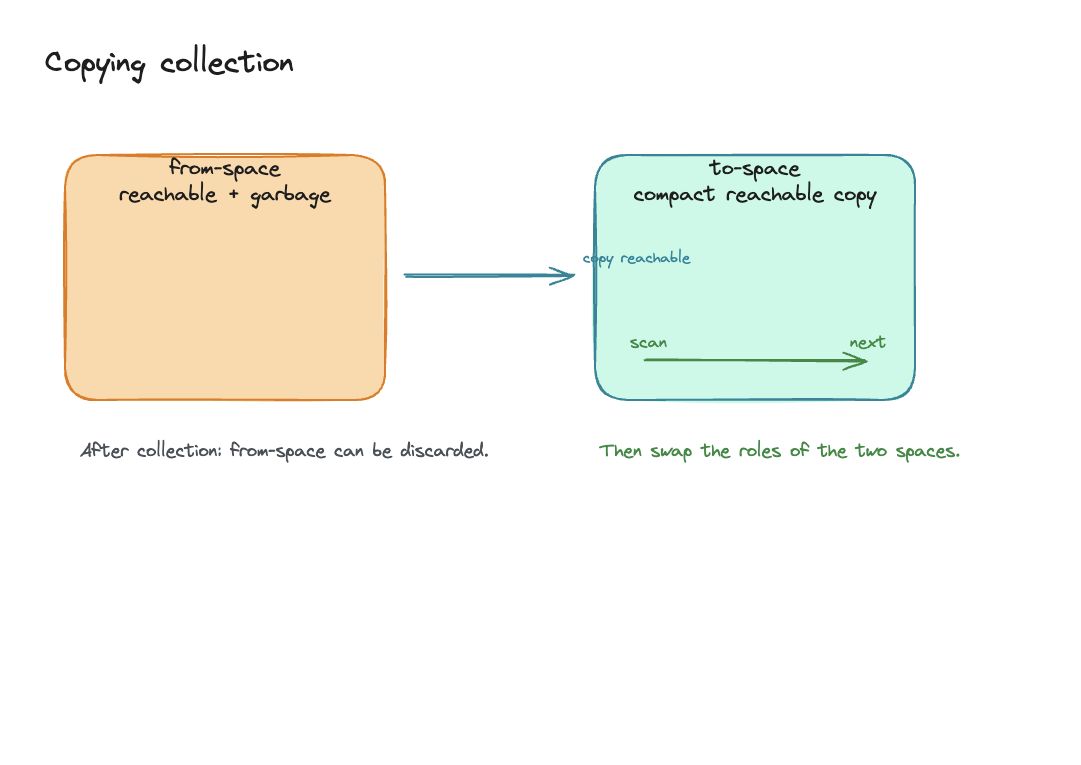
转发指针(Forwarding Pointer)
复制记录 A 时,在其旧副本(from-space)的某个字段中存入转发指针,指向新副本(to-space)的位置。之后任何指向 A 的指针都可以通过转发指针找到新位置。
function Forward(p)
if p 指向 from-space
if p.f1 指向 to-space // 已复制,f1 是转发指针
return p.f1
else // 未复制
for each field fi of p
next.fi ← p.fi
p.f1 ← next // 安装转发指针
next ← next + sizeof(record p)
return p.f1
else
return p // 非指针或已指向 to-space
Cheney's Algorithm(广度优先复制)
使用 BFS,无需栈或指针反转:
scan ← next ← beginning of to-space
for each root r
r ← Forward(r)
while scan < next
for each field fi of record at scan
scan.fi ← Forward(scan.fi)
scan ← scan + sizeof(record at scan)
scan和next将 to-space 分为三个区域:[begin, scan):已复制且已扫描(所有指针已转发);[scan, next):已复制但未扫描(BFS 工作队列);[next, limit):空闲区域。
局部性问题
BFS 复制的缺点:若记录 a 指向记录 b,复制后 a 和 b 可能相距很远(因为 BFS 按距根的距离排列)。
改进:Semi-depth-first forwarding(混合算法)——在复制对象时,尽量把某个子对象复制到相邻位置,兼顾局部性和实现简单性。
成本
- 时间:O(R)(只处理可达数据,无 sweep 阶段);
- 空间:堆被分为两半,浪费一半内存;
- 优点:复制后可达对象连续排列,自动 compaction,没有 external fragmentation;
- 缺点:Cheney BFS 的对象排列按“距根距离”分层,相关对象可能不相邻,局部性可能变差;
- 摊销成本: 当 时趋近于 0。
Generational Collection(分代收集)
观察
大多数新创建的对象很快死亡;存活多次收集的对象很可能长期存活。
分代策略
将堆划分为多个代(generations):
- G₀:最年轻的一代;
- G₁:比 G₀ 老;
- G₂:比 G₁ 老;以此类推。
收集策略
- 频繁收集 G₀(年轻代垃圾比例高,效率高);
- 偶尔收集 G₁, G₂, …(老年代);
- 收集 Gᵢ 时,根包括:程序变量 + 老年代中指向 Gᵢ 的指针。
记忆集(Remembered Set)
老年代对象指向新生代的情况很少见,但必须处理。编译器通过 write barrier 记录这些指针:
| 机制 | 原理 |
|---|---|
| Remembered list | 每次更新 b.fi ← a(b 老,a 新),把 b 加入向量 |
| Remembered set | 用对象内的一位标记 b 是否已在向量中,避免重复 |
| Card marking | 将内存分为固定大小的 card;更新时标记对应 card;GC 扫描被标记的 card |
| Page marking | 利用虚拟内存系统的 dirty bit;或写保护页面,由缺页异常处理程序记录 |
成本
- 若 G₀ 中 ,则每字摊销成本约 1 条指令;
- 维护 remembered set 的开销:约 10 条指令/指针更新。
Incremental Collection(增量收集)
问题
即使 GC 总时间只占计算时间的几个百分点,也可能造成长时间停顿,对交互式/实时程序不利。
三色标记(Tricolor Marking)
| 颜色 | 含义 |
|---|---|
| White | 尚未访问 |
| Grey | 已访问,但子节点尚未处理(在栈/队列中) |
| Black | 已访问,且所有子节点已处理 |
不变式:
- 黑节点不指向白节点;
- 所有灰节点都在收集器的 grey-set 中。
增量/并发算法
收集器与 mutator(程序)交替执行,mutator 的每次写/读可能破坏不变式,需通过 barrier 修复:
| 算法 | Barrier 类型 | 策略 |
|---|---|---|
| Dijkstra et al. | Write barrier | mutator 把白指针 a 存入黑对象 b 时,将 a 染灰 |
| Steele | Write barrier | mutator 把白指针 a 存入黑对象 b 时,将 b 染灰 |
| Boehm-Demers-Shenker | Write barrier (VM) | 全黑页面设只读;写入时缺页异常,将该页所有对象染灰 |
| Baker | Read barrier | mutator 获取白对象指针时,将其染灰;mutator 永远看不到白对象 |
| Appel-Ellis-Li | Read barrier (VM) | 从含非黑对象的页面读指针时,缺页异常将该页全染黑 |
Baker's Algorithm
基于 Cheney 复制算法的增量收集:
- Flip:交换 from-space / to-space,转发所有根;
- mutator 恢复运行,但只能看到 to-space 指针;
- 每次分配时,扫描几个
scan处的指针(推进 scan); - 每次读取记录字段后,检查是否为 from-space 指针,若是则立即转发。
开销:每次 fetch 后需 2~3 条额外指令检查指针,约 20% 性能开销。
Interface to the Compiler(编译器接口)
GC 虽由运行时执行,但编译器需提供以下支持:
1. 快速分配
复制收集的 to-space 是连续空闲区,分配极快:
// 内联展开的分配代码(N 为记录大小)
if next + N > limit then goto GC
result ← next
next ← next + N
// 初始化字段(与有用计算融合)
通过内联、寄存器保存 next/limit、批量检查等优化,每次分配约 4 条指令。
2. 描述数据布局
GC 必须知道每个记录的:
- 总大小;
- 哪些字段是指针。
静态类型语言(Tiger, Pascal):每个对象首字指向类型描述符(type-descriptor),描述大小和指针位置。开销:每对象 1 字。
面向对象语言(Java):描述符指针本就用于动态方法查找,无额外 GC 开销。
3. 指针映射(Pointer Map)
编译器必须告诉 GC:每个 GC 起点处,哪些寄存器和栈位置包含指针。
- GC 起点(safe point):每次
alloc调用、每次函数调用(可能间接调用 alloc); - 以返回地址为键:GC 从栈顶向下扫描,每个返回地址对应一个 pointer-map 条目,描述下一帧的指针布局;
- Callee-save 寄存器需特殊处理:调用者需知道被调用者保存的 callee-save 中哪些是指针、哪些继承自上层。
4. 派生指针(Derived Pointers)
编译器可能生成指向记录中间或外部的指针:
t1 ← a - 2000 // 派生指针,指向数组 a 的前面
...
t3 ← M[t1 + i] // 实际访问 a[i-2000]
问题:GC 时 t1 不指向对象开头,relocation 后会失效。
解决:
- Pointer map 记录每个派生指针及其基指针;
- GC 将 a 移到 a' 时,调整 t1 ← t1 + (a' − a);
- 派生指针隐式保持基指针存活(即使基指针在源代码中看似已死)。
- GC 目标:自动回收不可达堆内存;使用可达性作为 conservative approximation。
- Mark-Sweep:两阶段(标记可达 + 清除未标记);成本 O(H);有碎片问题;可用显式栈或指针反转实现 DFS。
- Reference Counting:即时回收、增量式,但无法处理循环、赋值开销大。
- Copying Collection:Cheney BFS 复制可达数据到 to-space;无碎片、时间 O(R)、但浪费一半空间;可用混合算法改善局部性。
- Generational:利用"新对象快死"的观察,重点收集年轻代;通过 write barrier(remembered set / card marking)处理跨代指针。
- Incremental:通过三色标记 + read/write barrier 实现 mutator 与 collector 并发;Baker 算法基于复制收集,read barrier 约 20% 开销。
- Compiler Interface:快速分配内联、类型描述符、pointer map(以返回地址为键)、派生指针处理。