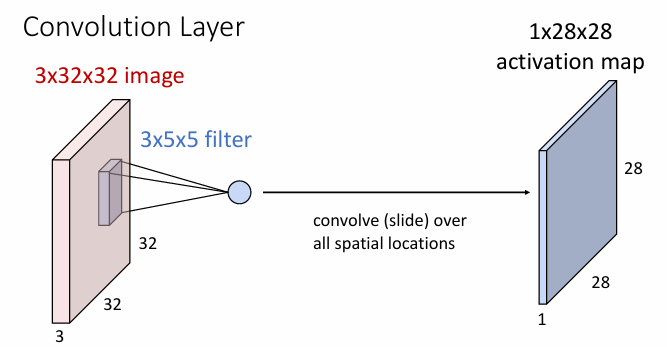
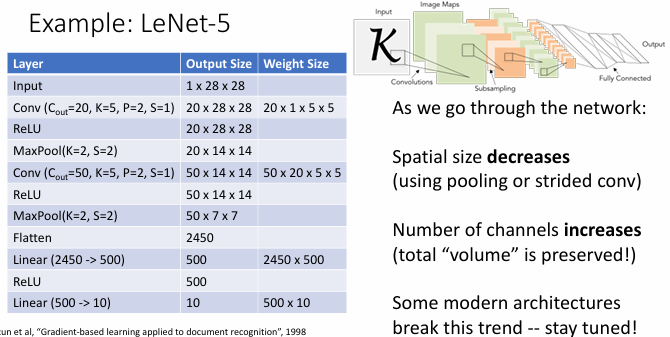
Convolution Layer
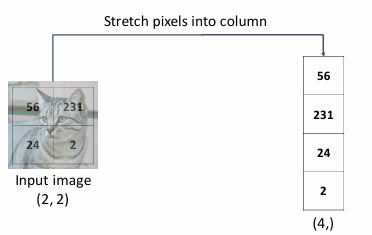
Neither Linearclassifier nor the two dimensional nenueral network respect the spatial structure on images!
they convert the 3x32x32 image into a 3072x1 vector.Stretch pixels into column.
A convolutional layer applies a set of filters to the input image.
single filter
multiple filters
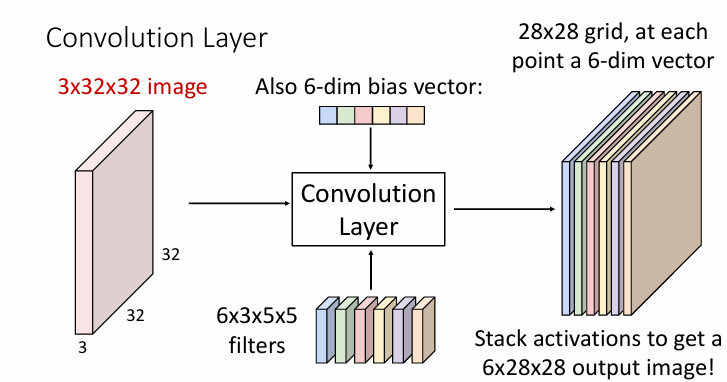
For the output of the convolutional layer, we can consider them as
- 6 activation maps,each 1x28x28
- 28x28 grid,at each point,6-dimensional vector
Multiple input
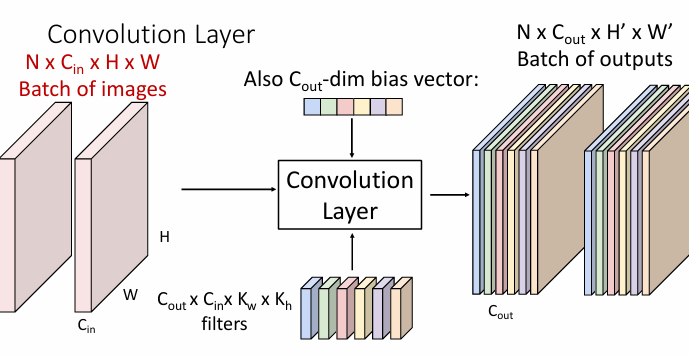
Summary
- input
- filter
- bias
- output
will disappear in the output since it is the same in the input and the filter.
Connect multiple hidden layers
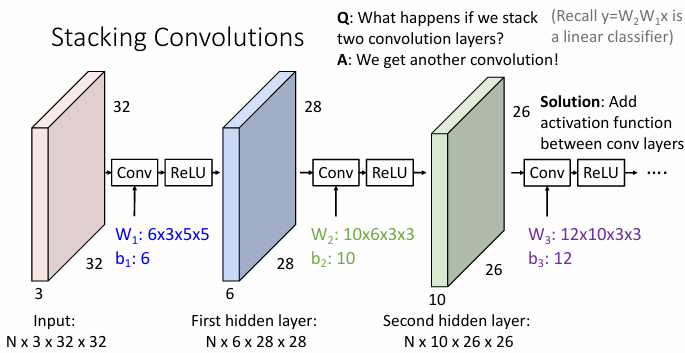
-
for linear classifier,the weight matrix(C,D);each row could reshape as a template image.多少种类别就有多少个模板。
-
for neural network,the weight matrix W1(H,D);each row could reshape as a Bank of whole-image templates与Hidden Layer H个神经元一一对应。
-
for convolutional neural network, local image templates (Often learns oriented edges, opposing colors),表现局部特征

padding
For input size ,filter size
The output size is
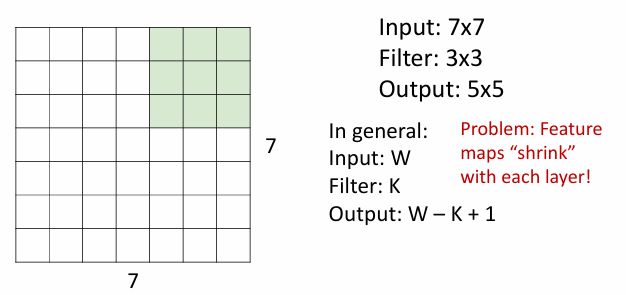
By adding additional pixels around the input image(usually 0 padding), we can control the output size.
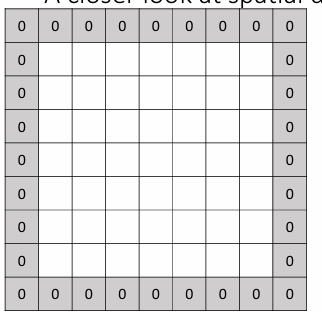
Therefore, the output size is
Receptive Field
在卷积神经网络(CNN)中,激活的感受野(receptive field)是指输入图像中对某个激活值影响最大的区域。换句话说,感受野是指在输入图像中,某个特定的神经元(或激活值)能够“看到”或“感知到”的那一部分区域。感受野的大小和位置会影响神经网络对图像特征的提取和理解。
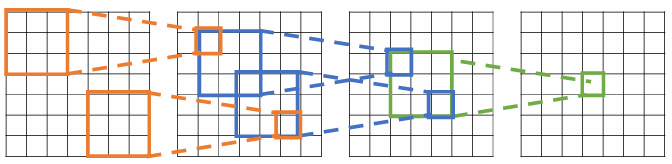
Each successive convolution adds to the receptive field size With layers the receptive field size is
这个也不难理解,以上图最后的输出图像的中心位置的元素为例(假设其为C3,有C2,C1,C0),它在前一层C2的感受野是,而这的区域的感受野是C3区域中,中心位于其中的filter的感受野,要考虑其大小,只需要在四个角扩展边长即可,边长会增加.
所以对于层,感受野的大小是(末层感受野)+,(L次扩展)
Problem: For large images we need many layers for each output to “see” the whole imageStride
Solution: Downsample inside the networkBy increasing the stride, we extend the receptive field.
Now the output size should be
1是一开始的位置,是接下来可选的位置。
Input volume: 3 x 32 x 32, 10 3x5x5 filters with stride 1, pad 2
Output volume: 10x((32-5+2*2)/1+1)=10x32x32 (Whoa,same size!)
Number of learnable parameters:
- Parameters per filter:
- Total:
Number of multiply-add operations:
Other types of convolution
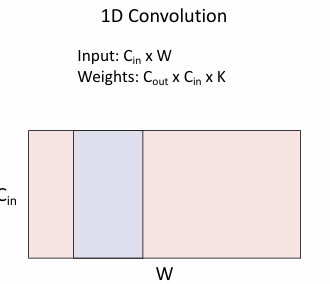
目前为止看到的是2D的卷积,实际上还有1D和3D的卷积。
1D的卷积:
- 输入:
- 输出:
- 参数:
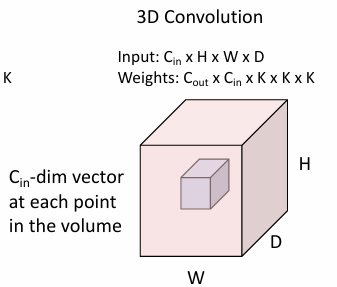
3D的卷积:
- 输入:
- 输出:
- 参数:
-
Input:
-
Hyperparameters:
- Kernel size:
- Number of filters:
- Padding:
- Stride:
-
Weight matrix: (giving filters of size )
-
Bias vector:
-
Output size: where:
Pooling Layers
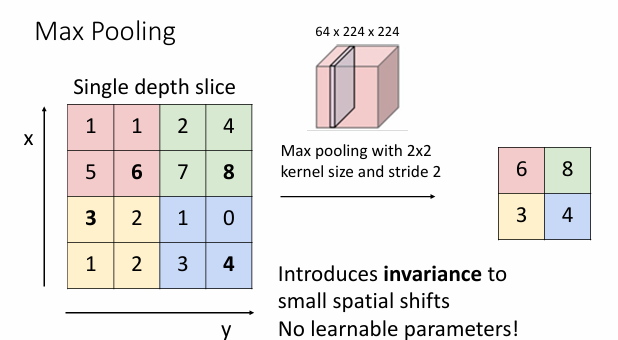
Pooling layer is a downsampling layer.
在卷积神经网络(CNN)中,池化(Pooling)层是一种下采样层,用于减少特征图的尺寸,同时保留重要的特征信息。池化层的主要目的是降低计算复杂度、减少内存使用,并在一定程度上控制过拟合。
Types of Pooling
- Max Pooling:
- 在一个池化窗口内选择最大值作为输出。
- 这种方法可以保留最显著的特征。
- Average Pooling:
- 在一个池化窗口内计算平均值作为输出。
- 这种方法可以平滑特征图。
Parameters of Pooling
- 池化窗口大小(Kernel Size):定义了池化操作的区域大小。
- 步幅(Stride):定义了池化窗口在特征图上移动的步长。
- 填充(Padding):有时会在特征图的边缘添加额外的像素,以便池化窗口可以完全覆盖特征图。
Effect of Pooling
- 降维:通过减少特征图的尺寸,降低了模型的计算复杂度。
- 特征不变性:通过池化操作,模型对输入的微小变化(如平移、旋转)具有更强的鲁棒性。
- 防止过拟合:通过减少参数数量,降低了模型过拟合的风险。
池化层通常在卷积层之后使用,以便在提取特征后进行下采样。
Key characteristics of pooling layers:
-
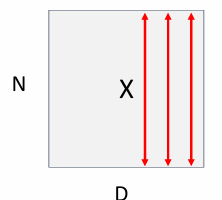
Input size:
-
Hyperparameters:
- Kernel size:
- Stride:
- Pooling function: max pooling or average pooling
-
Output size: where:
-
Learnable parameters: None
实际上是与卷积filter的作用是类似的,都是把一个局部映射成一个值来缩小,但池化比较EZ。且池化不会改变通道数。
Example
 in fact,the max pooling already add some non-linearity to the network,some after this, if we don't use ReLU,the result is still correct.
in fact,the max pooling already add some non-linearity to the network,some after this, if we don't use ReLU,the result is still correct.
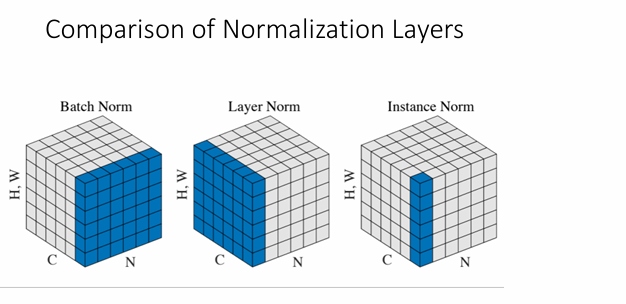
Batch Normalization
Idea: “Normalize” the outputs of a layer so they have zero mean and unit variance
Why?Because Deep Networks are very hard to train!
进行批量归一化(Batch Normalization)的主要原因是为了减少“内部协变量偏移”(internal covariate shift),从而改善模型的优化过程。具体来说,批量归一化通过将每一层的输出标准化为零均值和单位方差,来稳定和加速神经网络的训练过程。这种标准化操作是可微的,因此可以在网络中作为一个操作符使用,并通过反向传播进行训练。
具体来说
(Running) average of values seen during training
(Running) average of values seen during training
is a small constant to avoid division by zero.
and are learnable parameters,when and ,the output is the same as the input.
上面展示的是按Batch的计算,即按样本计算,最后会得到的均值和方差张量,然后进行广播,得到的均值和方差张量。

还有按layer和Instance的计算